Dane. Bazy danych. Duże zbiory informacji zapisanych w formie tabel. Różne formaty danych: numeryczne, tekstowe, alfanumeryczne. Jak je interpretować ? Jak prezentowane dają nam bezcenne informacje umożliwiające rozumienie przedstawianego procesu ? W tym wpisie postaram się zaprezentować schemat postępowania i myślenia, który umożliwia z jednej strony identyfikowanie przyczyn źródłowych zakłóceń w analizowanym procesie i definiowanie działań naprawczych, a z drugiej strony pozwala wyłapywać pewne zależności, które są sygnałami do podejmowania działań dających wymierna korzyści.
I. Grupowanie Danych
Grupowanie danych to technika umożliwiająca przypisywanie etykiet do pojedynczych „linijek” (rekordów) zapisanych w postaci tabeli, które spełniają pewne założone przez nas kryteria. Podejście to umożliwia w następnym etapie prezentowanie danych w czytelnej i zrozumiałej formie w postaci różnych syntetycznych zestawień i wykresach. Etykiety można definiować praktycznie dowolnie, ważne natomiast jest aby realizowały swoje zadanie grupowania danych na mniejsze lub bardziej szczegółowy podgrupy. Przed przystąpieniem do ich określenia trzeba się dobrze zastanowić jakie chcemy wprowadzić, pod kątem ich późniejszego zastosowania w procesie interpretowania wyników. Nieprzemyślenie tego aspektu może prowadzić finalnie do niepełnej czytelności prezentowanych analiz i w konsekwencji podejmowania błędnych decyzji. Wspomnę również o tym, iż późniejsza konieczność przedefiniowywania etykiet w naszych bazach danych może pociągać za sobą dodatkowe koszty wprowadzenia zmian.
Stosowane są pewne standardy grupowania dla kilku specyficznych typów danych, które chciałem poniżej przedstawić:
– dane zawierające datę możemy pogrupować na: godziny, dni, tygodnie, miesiące, kwartały, półrocza, lata,
– dane sprzedażowe dotyczące lokalizacji naszych klientów możemy podzielić na: miasto, kraj, region, kontynent.
– naszych klientów możemy podzielić na grupy wiekowe np. 0-10 lat, 10-20 lat, 20-30 lat, 40-50 lat, 60-70 lat, 80+ lat
– dane osobowe klientów możemy podzielić na: mężczyzna, kobieta, dziecko.
– udział w sprzedaży lub wydatkach w pewnym horyzoncie czasowym: TOP10, TOP25, TOP50, TOP100, . . . LESS25, LESS10
– zestawienia cashflow można podzielić na: przychody/wydatki. Wydatki z kolei można podzielić na: żywność, edukacja, dzieci, rozrywka, wakacje, samochód, dom, . . .
Istnieją zasadniczo dwa sposoby przypisywania etykiet do pojedynczych rekordów w naszych tabelach danych: automatyczny i manualny.
Automatyczny to taki, który można zapisać za pomocą algorytmu, którego działanie będzie automatycznie przypisywało etykiety do naszych danych.
Manualny z kolei to taki, który wymaga definiowania etykiety dla każdego rekordu indywidualnie i z racji tego jest dużo bardziej czasochłonny.
Osobiście jestem zwolennikiem podejścia automatycznego gdyż raz zdefiniowany nie wymaga poświęcania mu wiele uwagi.
Poniżej dwa przykłady automatycznego sposobu definiowania etykiet:
1. Automatyczne definiowanie etykiet grupujących daty na różne okresy: tygodnie, miesiące, kwartały, lata i ich wzajemne połączenie. Poniej pokazana jest przykładowa tabela z lista dat po lewej stronie i a po prawej automatycznie przypisywane są etykiety: tydziń, miesiąc, kwartał, rok i ich wzajemne łączenia. Pod tabela sa wylistowane zastosowane funkcje.
Dodatkowo zamieszczam link do pliku z prezentowaną tabelą.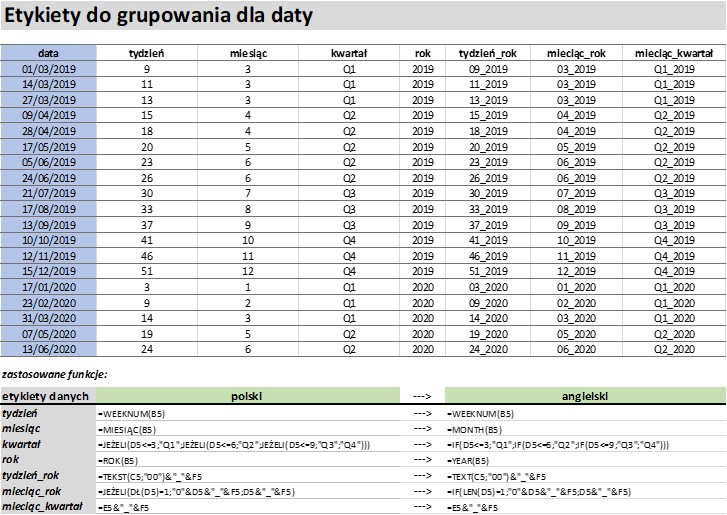
2. Automatyczne definiowanie etykiet dla danych tekstowych zawierających pewną frazę w całym tekście. W poniższym przykładzie jest to fraza „OPŁATY-”, której całkowita długość ma 14 znaków np.tranzakcja posiadająca w tytule składnię: „telewizja OPŁATY-NetFlix listopad ’19 przelew” da w konsekwencji zastosowania prezentowanej funkcji odnoszącej się tabeli referencyjnej etykietę „DOM_OPŁATY”. Pod tabela sa wylistowane zastosowane funkcje.
Dodatkowo zamieszczam link do pliku z prezentowanym przykładem automatyzacji definiowania etykiet tekstowych.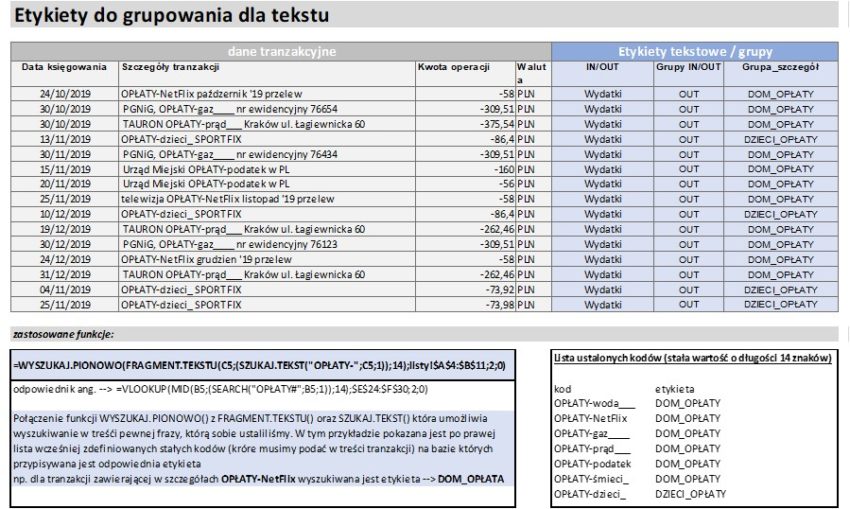
W dalszej kolejności chciałem zaprezentować dwa przykłady dotyczące dwóch różnych obszarów.
1. Analiza wydatków i przychodów w budżecie domowym – Przykład I
2. Analiza kursów jednej z instrumentów finansowym notowanego na giełdzie – Przykład II
Przykład I – Analiza wydatków domowych.
Brzmi może na początek trochę nudno, ale czy tak musi być ? Mamy z takim tematem czasami negatywne skojarzenia z przeszłości, natomiast celem tego przykładu jest pokazanie jak można to zdefiniować i zautomatyzować tak aby nie zajmowało więcej niż 10 min miesięcznie. Form prowadzenia budżetu domowego może być wiele: papierowa, cyfrowa w formie arkusza kalkulacyjnego lub bezpośrednio na poziomie naszego konta bankowego (obecnie banki oferują pewne wbudowane funkcjonalności na swoich platformach internetowych). Sam wybór formy dopasowanej do naszych potrzeb to może temat na osobny wpis ja natomiast chciałem zaprezentować opcje grupowania i analizy danych dla wydatków domowych w oparciu o arkusz kalkulacyjny. Dane źródłowe będą pochodziły z raportu transakcji konta bankowego stosowanego przez nas do realizowania wydatków, na który również otrzymujemy wynagrodzenie. Przykładowe dane zawierają wydatki i przychody w okresie 1 kwartału i dotyczą przeciętnej rodziny 4 osobowej (2+2) mieszkającej w średniej wielkości mieście w szeregowcu z małym ogródkiem generujących miesięczny przychód netto na poziomie ok 10.000+ zł. Przykładowe dane analityczne są dostępne pod poniższym linkiem – dane w formie arkusza kalkulacyjnego.
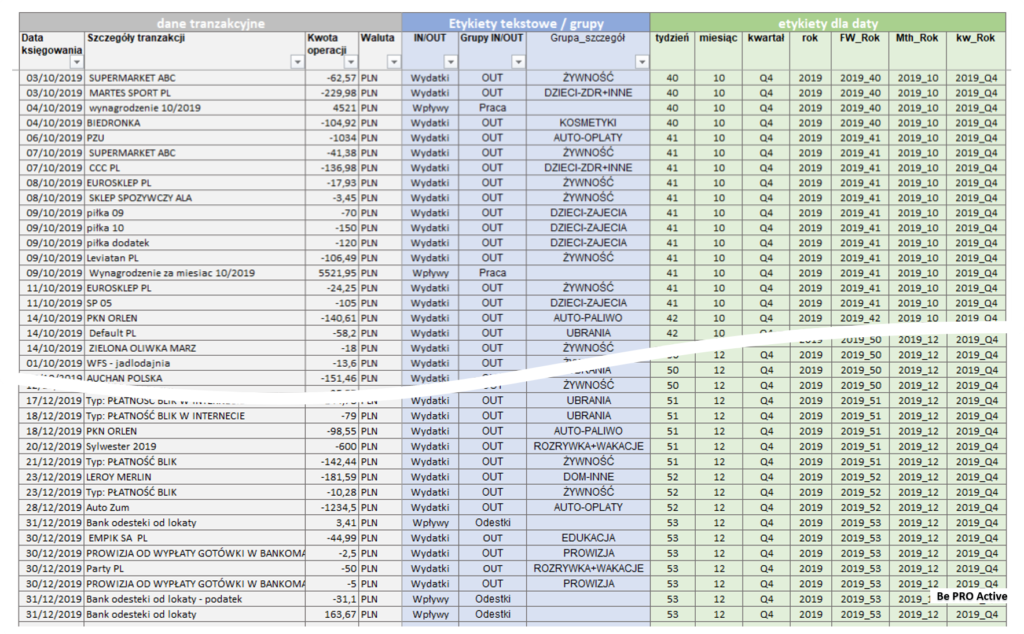
W przykładzie są zastosowane dwa rodzaje etykiet:
1. Etykiety tekstowe – sekcja niebieska. 3 kolumny z etykietami wg zasady jak poniżej:
– IN/OUT – dla podziału wydatki/wpływy
– Grupy IN/OUT – dla dokładniejszego podziału w ramach wpływów (praca, odsetki, extra – dla okazjonalnych przychodów)
– Grupa_szczegół – dla dokładnego grupowania wydatków – sekcja niebieska (jest częściowo automatyczna a częściowo manualna) W ramach tego pola są etykiety: ŻYWNOŚĆ, KOSMETYKI, AUTO-OPLATY, DZIECI-ZAJECIA, AUTO-PALIWO, UBRANIA, DOM-INNE, PROWIZJA, ROZRYWKA+WAKACJE, EDUKACJA, DAROWIZNA, DOM_OPŁATY, DZIECI_OPŁATY, DZIECI-ZDR+INNE, KOSMETYKI.
2. Etykiety dla dat i okresów – sekcja zielona (to jest w 100% zautomatyzowane) – szczegóły zostały zaprezentowane w sekcji automatycznego przypisywanie etykiet.
Przykład II – Analiza kuru akcji notowanych na giełdzie
.Dane cen transakcji zrealizowanych dla przykładowej akcji spółki ABC, za okres jednego dnia rejestrowanych w 30 minutowych interwałach czasowych. Przeglądanie samej tabeli z danymi raczej nie jest praktykowane w tym obszarze, gdyż nie dostarcza to zbyt dużo wartości dodanej. Krytyczne jest natomiast pokazywanie zmienności. Dla przykładu zaprezentuje grupowanie danych dla późniejszej prezentacji danych w formie wykresu świecowego.
Do prezentacji graficznej potrzebujemy 4 etykiety, które zostały zaznaczone w poniższej tabeli:
– cena otwarcia – będąca ceną pierwszym transakcji w wybranym do prezentacji interwale czasowym.
– cena zamknięcia – będąca cena ostatniej transakcji w wybranym do prezentacji interwale czasowym.
– cena minimalna – będąca cena minimalną transakcji w wybranym do prezentacji interwale czasowym.
– cena maksymalna – będąca cena maksymalną transakcji w wybranym do prezentacji interwale czasowym.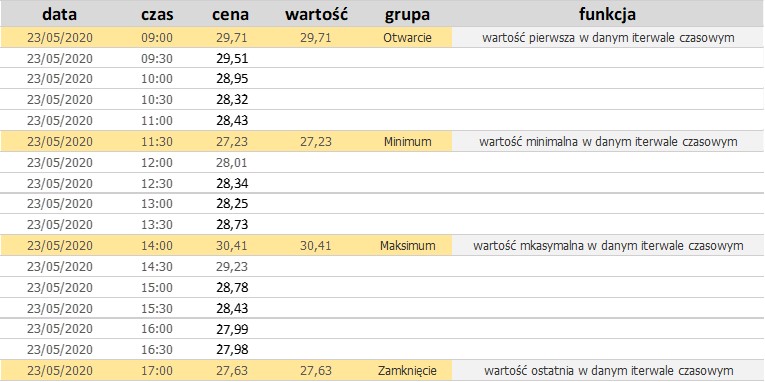
Następnie przejdę do tematu syntetycznej i graficznej prezentacji naszych danych, dla których udało nam się do tej pory ustalić procedury definiowania wymaganych etykiet.
II. Prezentacja Danych
Blisko 70% bodźców ze świata zewnętrznego odbieranych jest przez nasz zmysł wzroku. To największy udział. Pozostałe 30% przypada na słuch, dotyk, węch, smak. Fakt ten uzmysławia znaczenie graficznej prezentacji analizowanych danych. Obecnie jest dostępnych sporo programów posiadających wbudowany interfejs graficzny do prezentacji danych. Ja dla omówienia tematu będę stosował arkusz kalkulacyjny. Postaram się przedstawić kilka możliwości prezentowania danych w formie tabeli syntetycznej i różnych wykresów dla dwóch przykładów prezentowanych w tym wpisie.
Prezentacja danych w oparciu o ustalone etykiety dla Przykadu I
– Forma tabeli syntetycznej [tabela przestawna] pokazująca skumulowane wartości w zdefiniowanych przez nas grupach, z wbudowaną opcją zaznaczania kolorów [formatowanie warunkowe] w kolumnie %. Dla wartości DETLY powyżej 25% zastosowano kolor zielony (oczekiwany rezultat), dla przedziału od 25 do15% żółty, poniżej 15% czerwony.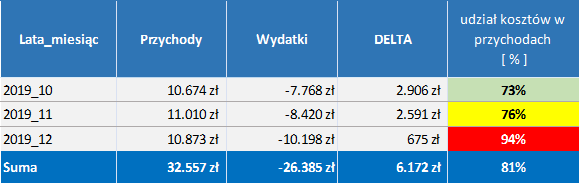
– Wykres kołowy prezentujący udział poszczególnych grup wydatków w całości z pokazaniem udziału procentowego.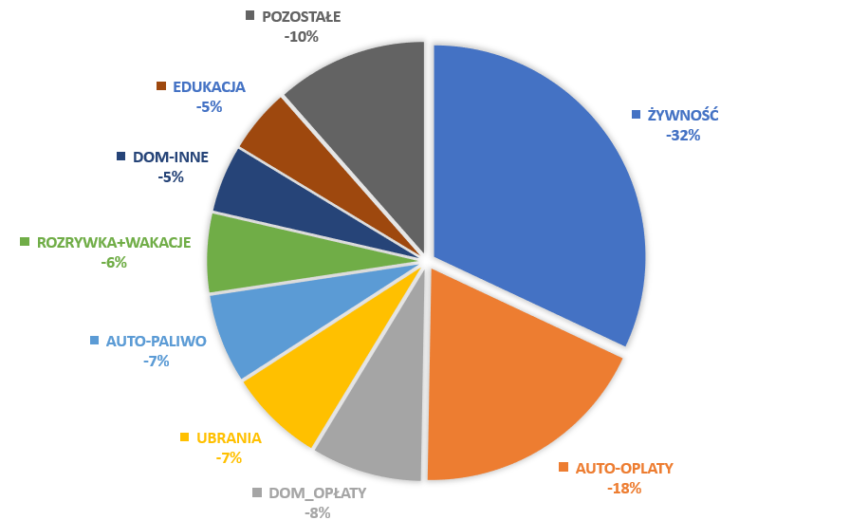
– wykres treemap – kolaż, dla wydatków prezentujący udział poszczególnych elementów w całości z pokazaniem udziału procentowego
– Wykresu słupkowego skumulowany pokazujący udziały każdego z elementów wydatków w poszczególnych miesiącach.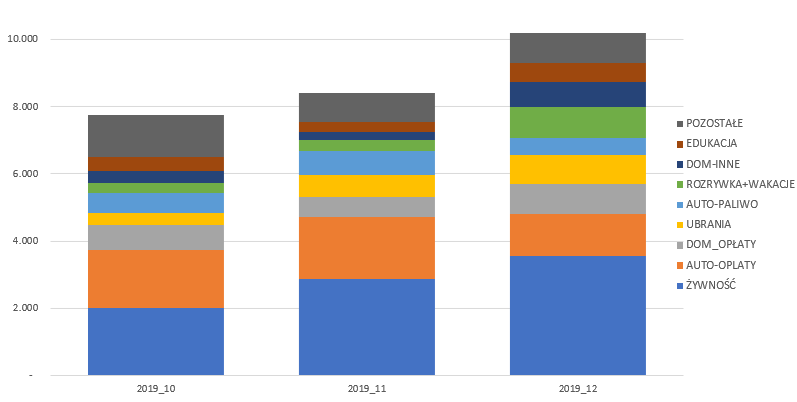
Prezentacja danych w oparciu o ustalone etykiety dla Przykładu II
– wykres świecowy stosowany przy prezentowaniu notowań giełdowych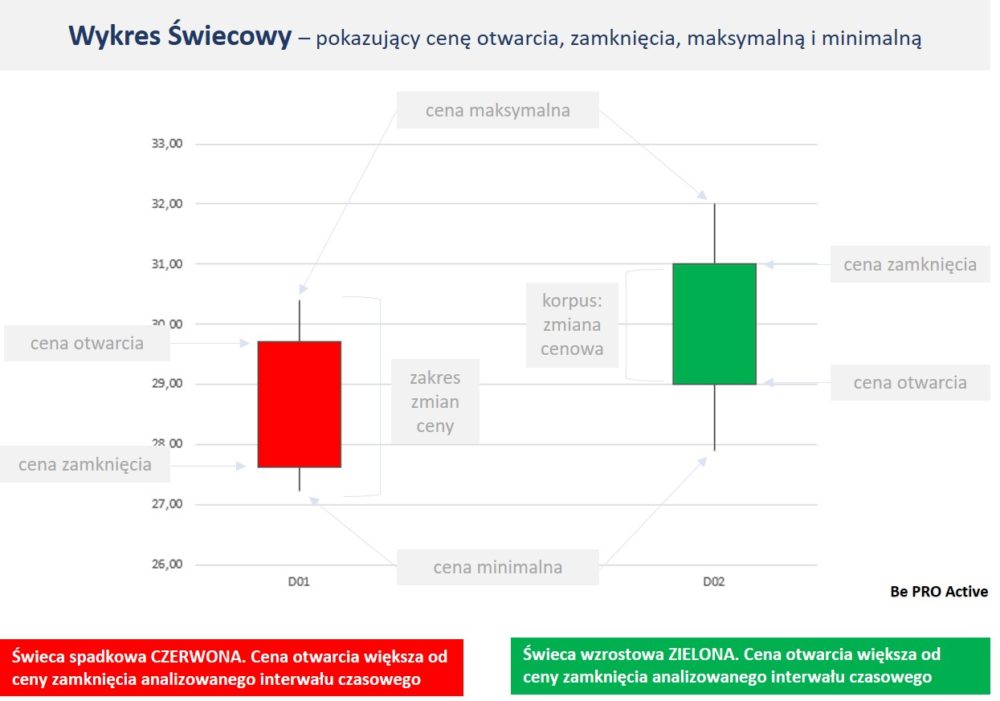
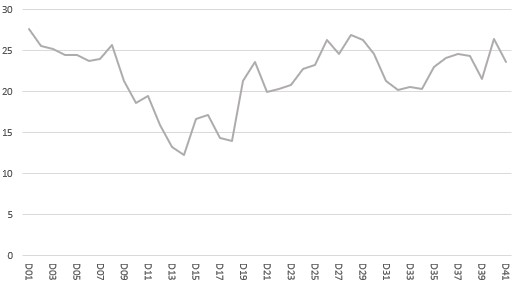
– wykres liniowy versus wykres świecowy do prezentacji notowań instrumentów notowanych na giełdach finansowych. Pierwszy to wykres świecowy pokazujący amplitudę notowań akcji w cyklu dziennym. Drugi to zwykły wykres liniowy pokazujący wartości ceny akcji na zamknięcie sesji w zdefiniowanym do wyświetlania okresie (na przykładowym wykresie jest to interwał dniowy). Weźmy dane dla Dnia 19 [D19], w którym to cena na zamknięcie sesji wyniosła 21,34 zł natomiast faktyczna amplituda notowań w tym dniu wyniosła 16 zł – pomiędzy 22,56 zł a 6,56 zł. Patrzenie tylko na wykres liniowy daje nam „spłaszczone” wyniki, natomiast wykres świecowy daje możliwość wglądu w pełną zmienność jaka występuje w notowaniach.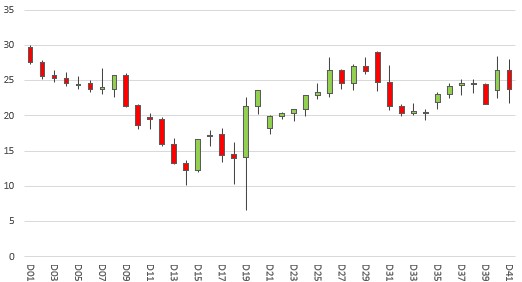
To tylko kilka przykładów żeby pokazać przyświecającą temu logikę. Czytelne graficzne prezentowanie danych daje syntetyczny wgląd pokazujący jak działają nasze procesy. Ich właściwa interpretacja dodatkowo stanowić istotny element kontroli jak również jest bazą do kolejnego aspektu jakiem jest podejmowanie decyzji.
III. Podejmowanie decyzji
Do tej pory zebraliśmy dane. Ustaliliśmy etykiety oraz logiki przypisywania ich do naszych danych częściowo realizowane automatycznie a częściowo manualnie. Określiliśmy graficzną prezentację naszych danych w postaci syntetycznych zestawień oraz różnego rodzaju wykresów. Teraz przejdę do najważniejszego tematu jakim jest kontrola i podejmowanie decyzji, który tak naprawdę jest głównym cel dla którego realizowane są pierwsze dwa elementy.

Dane obrazują pewien proces. Syntetyczna i graficzna ich prezentacja (w postaci tabel syntetycznych i różnego rodzajów wykresów) umożliwia zrozumienie czy on działa poprawnie i osiągamy zamierzone rezultaty. Rezultatami mogą być:
– osiąganie odpowiedniego poziomu relacji wydatków do dochodów
– osiąganie pewnego limitu przychodów
– kontrola wydatków w zdefiniowanych obszarach
– kontrola wydatków w ramach zdefiniowanego budżetu
– osiąganie zamierzonego zwrotu z inwestycji kapitałowych
Podczas analizy, patrząc na zdefiniowane wykresy i metryki możemy uzyskać dwie odpowiedzi:
1. Odpowiedz pozytywną – „TAK” – jeśli wyniki procesu spełniają nasze wyznaczone kryteria i wtedy możemy sobie pogratulować i otworzyć przysłowiowego „szampana”.
2. Odpowiedz negatywna – „NIE” – która, otwiera drzwi do szczegółowej analizy co nie działa i wgłębienia się w przyczyny źródłowe zakłóceń w procesie i zdefiniowania działań naprawczych.
W praktyce częściej spotykamy się z elementami działającymi niepoprawnie wymagającymi usprawnień lub zmiany. Te sygnały są cennymi informacjami, których usprawnienie umożliwia nam rozwój i osiąganie coraz to lepszych rezultatów. Poniższy schemat przedstawia mapę procesu, który powinien być stosowany do analizy wyników jaki osiągamy w naszych procesach. Stosowany regularnie diametralnie zwiększa szanse powodzenia naszych działań i osiągania coraz to lepszych rezultatów.
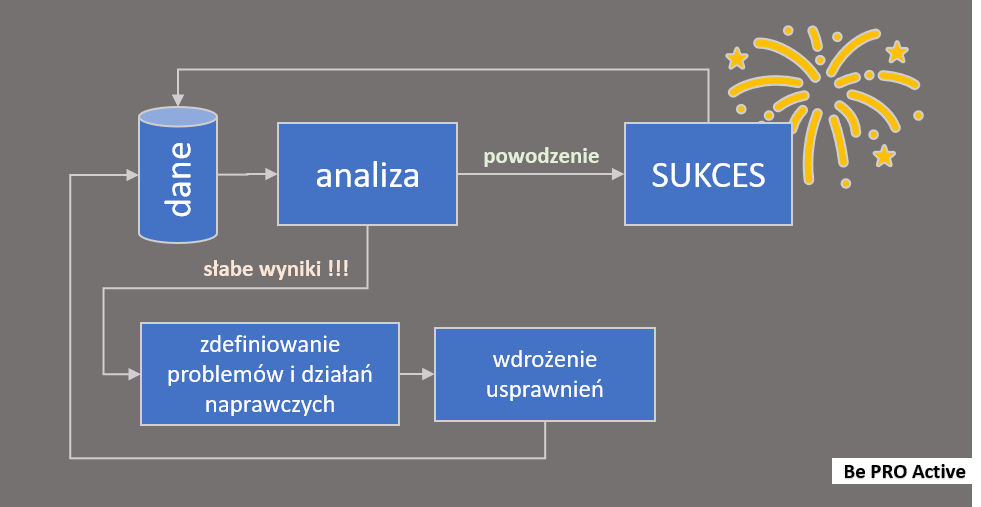
Jakie mirniki stosować dla naszych procesów ? Jakie podejście zastosować do ich zdefiniowania ? Tak naprawdę wymaga to indywidualnego przepracowania obszaru, który chcemy kontrolować. Poniżej zaprezentuję rozwiązania dla dwóch prezentowanych przykładów.
Analiza dla Przykładu I
Dane wpywów i wydatków za Kwartał 4 2019 r pokazują, że moje koszty nie przekraczają przychodów. Z drugiej jednak strony moje kryterium jest, żeby koszty nie stanowiły więcej niż 75% moich przychodów i to nie jest spełnione, W anlizowanym okresie stanowią one 81%, czyli zostały przekroczone o 6% co daje przekroczenie o kwotę 1.975 zł. Znając wyniki mogę teraz przystąpić do analizy źródła tego faktu.
Poszukiwanie przyczyn. Z wykresu treemap widzę, że największy odział w wydatkach ma żywność i stanowi ona 32% wszystkich wydatków.
Następnie sprawdzam teraz jak wydatki w tej grupie kształtowały się w poszczególnych miesiącach w Q4’19. Ze sprawdzenia wynika, że przekroczenie nastąpiło w grudniu, który całościowo wygenerował największe wydatki i wpłynął na wynik nie spełniający moich kryteriów.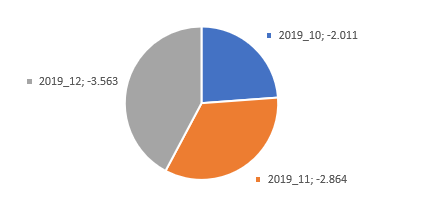
Zagłębiając się w szczegóły wydatków na żywność w grudniu sprawdzam gdzie jest największe źródło przekroczenia i sytuacja wygląda następująco:
– znaczący wzrost wydatków na jedzenie w restauracjach
– znaczący wzrost wydatków na napoje bezalkoholowe i alkoholowe
– duża ilość transakcji w automatach vendingowych
– ogólnie znaczący wzrost ilość rachunków płaconych w różnych sklepach spożywczych, co przekłada się na większą liczbę dojazdów do sklepów i zużycia benzyny.
Po powyższej analizie mogę przejść do zdefiniowanie działań naprawczych, które wyglądają następująco:
1. Ograniczenie wyjść do restauracji do jednego w tygodniu podczas weekendu.
2. Zredukowanie zakupu gotowych napojów.
3. Bazowanie na pożywieniu przygotowanym w domu i limitowanych przekąskach kupowanych w sklepach.
4. Lepsze planowanie zakupów [tworzenie listy zakupów do zrobienia] i ograniczenie wyjazdów na zakupy do maksymalnie 3 w ciągu tygodnia.
5. Jako dodatkowe działanie w Kwartale 1 2020, w przypadku nie osiągnięcia zakładanego pułapu 75% kosztów w stosunku do wydatków, byłaby zmiana formy użytkowania samochodu, za który muszę ponosić opłatę leasingową, która stanowi 18% moich wydatków. Opcją dostępną byłoby zakup tańszego używanego samochodu.
Analiza dla Przykładu II.
Inwestycje na rynku kapitałowym to nie tylko analiza wykresów będąca składową analizy technicznej ale również analiza fundamentalna. W tym przykładzie chciałem zaprezentować pewną sytuację, która miała miejsce na runku surowców a konkretnie na ropie. Posłużę się jednym z dostępnych instrumentów jakim jest ETF WisdomTree WTI Crude Oil notowanym na giełdzie w Londynie. W okresie drugiej połowy lutego, marzec i kwiecień 2020 rynek ropy się załamał i ceny ropy poszybowały w dół. Moją uwagę przyciągnął ogromny wzrost wolumenu na tym instrumencie w oparciu o ustawiony dla tego parametru skaner. Zacząłem analizować go pod kątem potencjalnej inwestycji.
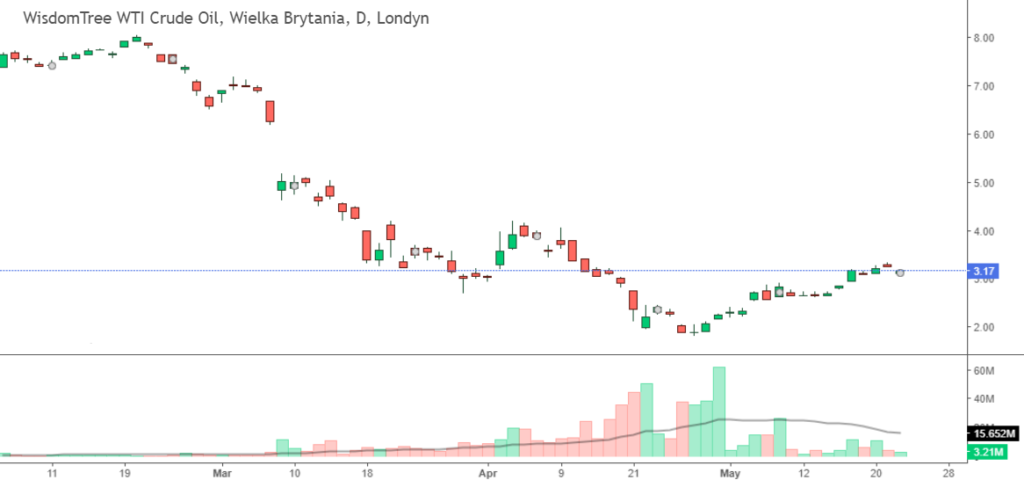
Poniżej moja analiza dla ETF CRUD:LN:
– końcem kwietnia na wykresie słupkowym wolumenu obrotów widać wzrost o ok 60 – 70%
– na wykresie świecowym można zauważyć spadek ceny od lutego do kwietnia z ok 8$ do 3$ co daje spadek o ponad 60%.
– początkiem mają następująca stabilizacja sytuacji gospodarczej w związku z pandemią wywołaną COVID-19
– w mediach pojawiły się informacje o stopniowym otwieraniu gospodarki – co będzie powodowało wzrost popytu na ropę.
– końcówka kwietnia to ograniczenie dynamiki spadków i zmniejszenie amplitudy zmienności cen.
– rekordowe obroty 30.04 to finalny katalizator do tego żeby podjąć decyzję o zakupie tego instrumentu.
Na bazie przeprowadzonej analizy podjąłem decyzję o wystawieniu zlecenia na zakup ETF WisdomTree WTI Crude Oil z limitem 2,30 $ za jednostkę na dzień 30.04.2020, które zostało zrealizowane. Dzisiaj na moment publikacji cena wynosi 3,15 $ co daje wzrost o 37% – i stanowi całkiem niezły wynik.
Podsumowując ten wpis chciałem jeszcze raz przypomnieć omawiane 3 główne elementy:
1. Grupowanie danych – definiowanie etykiet dla danych, które są generowane w analizowanych przez nas procesach, z podkreśleniem znaczenia na ich automatyzację.
2. Prezentacja danych – definiowanie syntetycznych zestawień i wykresów.
3. Podejmowanie decyzji – jako najważniejszy aspekt dla którego wykonywane są pkt 1 i 2, stanowiący podstawę skutecznego działania i optymalizacji procesów.
Życie przynosi ogromną ilość możliwości. Umiejętność ich wychwytywania jest bardzo cenna i może przynosić nam wymierne korzyści. Temat omawiany w tym wpisie w zakresie analizy danych to potężne narzędzie zwiększające prawdopodobieństwo osiągania powodzenia w podejmowanych przez nas działaniach. Zachęcam do jego stosowania i ciągłego usprawniania.
Jeśli chcesz dostawać powiadomienia o nowych wpisach na blogu be PRO active to zachęcam do zapisania się do listy dystrybucyjnej oraz o dołączenie do mediów społecznościowych powiązanych z blogiem be PRO active.





KG